
The reliability and performance of AI-enabled medical devices is only as robust as the data they are trained on. The type of data required for AI-enabled medical devices is dependent on the intended purpose and may include patient demographics, laboratory values, vital signs, clinical measurements, imaging (such as CT scans, radiographs, or MRI images), and time-series data (such as electrocardiogram signals or photoplethysmogram waveforms).
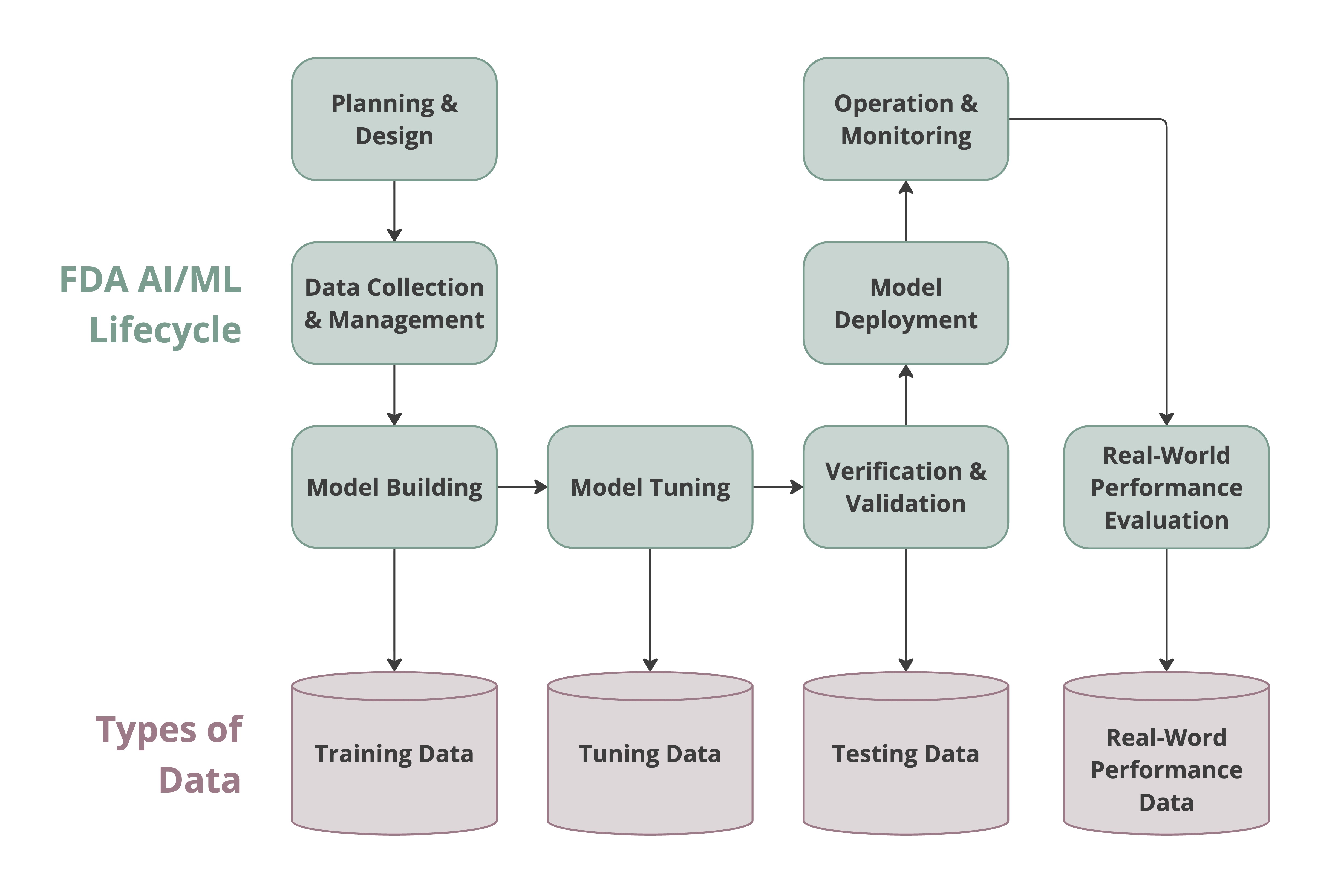
Data for AI-enabled medical devices serves different functions throughout the AI lifecycle:
- Training data is used to teach the AI model to recognize patterns and make predictions.
- Tuning data allows developers to tune model parameters and assess performance during development.
- Test data provides an unbiased assessment of model performance on unseen data.
- Real-world performance data collected post-market can inform ongoing model monitoring and identify potential safety issues.
The figure below shows different types of data required against the AI/ML lifecycle phases defined by the FDA.
Given the importance of data on the performance of AI-enabled medical devices, data management has become an emerging regulatory focus. Regulatory expectations have increased significantly in recent years. The EU AI Act dedicates Article 10 to data management of high-risk AI systems, while the FDA’s Jan 2025 draft guidance document on AI lifecycle management allocates 10% of its content to the topic. Data management will continue to become central to regulatory compliance as medical technology increasingly leverages AI to automate and improve clinical workflows.
Although the term is not defined in regulatory literature, international standards (such as ISO/IEC 22989 and ISO/IEC TR 24368) and regulatory guidance documents indicate that data management encompasses processes and tools involved in overseeing the entire data lifecycle – from its initial acquisition and preparation to its storage, maintenance, and disposal. This includes data collection, cleaning, annotation, quality checking, sampling, and augmentation. It also involves ensuring data representativeness, addressing bias, and maintaining version control and documentation to guarantee data integrity, suitability, and traceability.
In our experience, companies commonly make the mistake of developing AI models without considering a comprehensive end-to-end data management strategy. Given the current regulatory scrutiny on data management, failing to build a strong data management foundation at the start of design and development will likely lead to additional questions from regulatory authorities, expensive and time-consuming remediation, and delays to market access.
This article provides practical strategies for managing data in AI-enabled medical devices.
Integrate Within The QMS
Data management activities once occurred outside the medical device quality management system (QMS), with regulators expecting documentation only in submissions. This expectation is now shifting in that data management must be embedded within the QMS. The EU AI Act (Article 17) exemplifies this, where data collection and preparation processes must be integrated with AI QMS. Medical device companies should therefore define data management processes within their QMS to ensure consistent application across all AI-enabled devices throughout their lifecycle. These processes include procedures on the management of data throughout its lifecycle – from sourcing and preparation to retirement.
Apart from regulatory non-compliance, failing to integrate data management within the QMS will likely lead to inconsistent application of data management practices across multiple products and an inability to demonstrate traceability and control over processes that directly impact device safety and effectiveness.
Expert’s Secret #1: Define data management processes that include data collection, data requirements, data labelling, data pre-processing, data version control, and documentation.
Failing to define data requirements prior to collection may lead to data not being usable for ingestion, poor model performance, and bias and generalisability issues.
Plan For Data Management Early
Like other activities within design and development, it is crucial for data management activities to be planned early. This is consistent with how device companies approach early planning of design and development, risk management, software development, and usability engineering activities. When planned early during development (i.e., before design inputs), data management expectations can be aligned within cross-functional development teams. This also allows data management activities to be integrated with model training and validation activities. Data management plan should be defined during the planning stage of design and development and should include device-specific data management expectations.
Failing to plan data management activities early during design and development will likely require retroactive remediation to meet stringent regulatory expectations.
Expert’s Secret #2: Define a data management plan within the design and development file for each AI-enabled device.
Define Data Requirements Before Collection
As not all data can be used for all purposes, it is crucial to identify data requirements relating to each AI function prior to data collection. Consider data characteristics including validity, accuracy, completeness, consistency, traceability, uniformity, and representativeness to the intended patient population. This ensures that the data is fit for purpose for the intended algorithm.
Failing to define data requirements prior to collection may lead to data not being usable for ingestion, poor model performance, and bias and generalisability issues.
Expert’s Secret #3: Define data requirements as design inputs prior to data collection.
Implement Robust Data Versioning & Sequestration
The importance of data in AI cannot be overstated. Therefore, it is crucial that data storage processes ensure the integrity of data throughout the lifecycle. Storage processes should support version control, as different dataset versions may result in different model performance. The figure below shows the relationship between data, dataset and ML model – elements that should be version controlled:
- Data is the raw information collected from various sources, such as CT scans or ECG.
- Datasets are curated collections of data organized for a specific purpose. A dataset combines multiple data points with pre-processing (cleaning, annotation, and labelling), ultimately creating a structured package ready for model training.
- Models are the trained AI systems that learn patterns from datasets. A model is the output of training a specific algorithm on a specific dataset version.
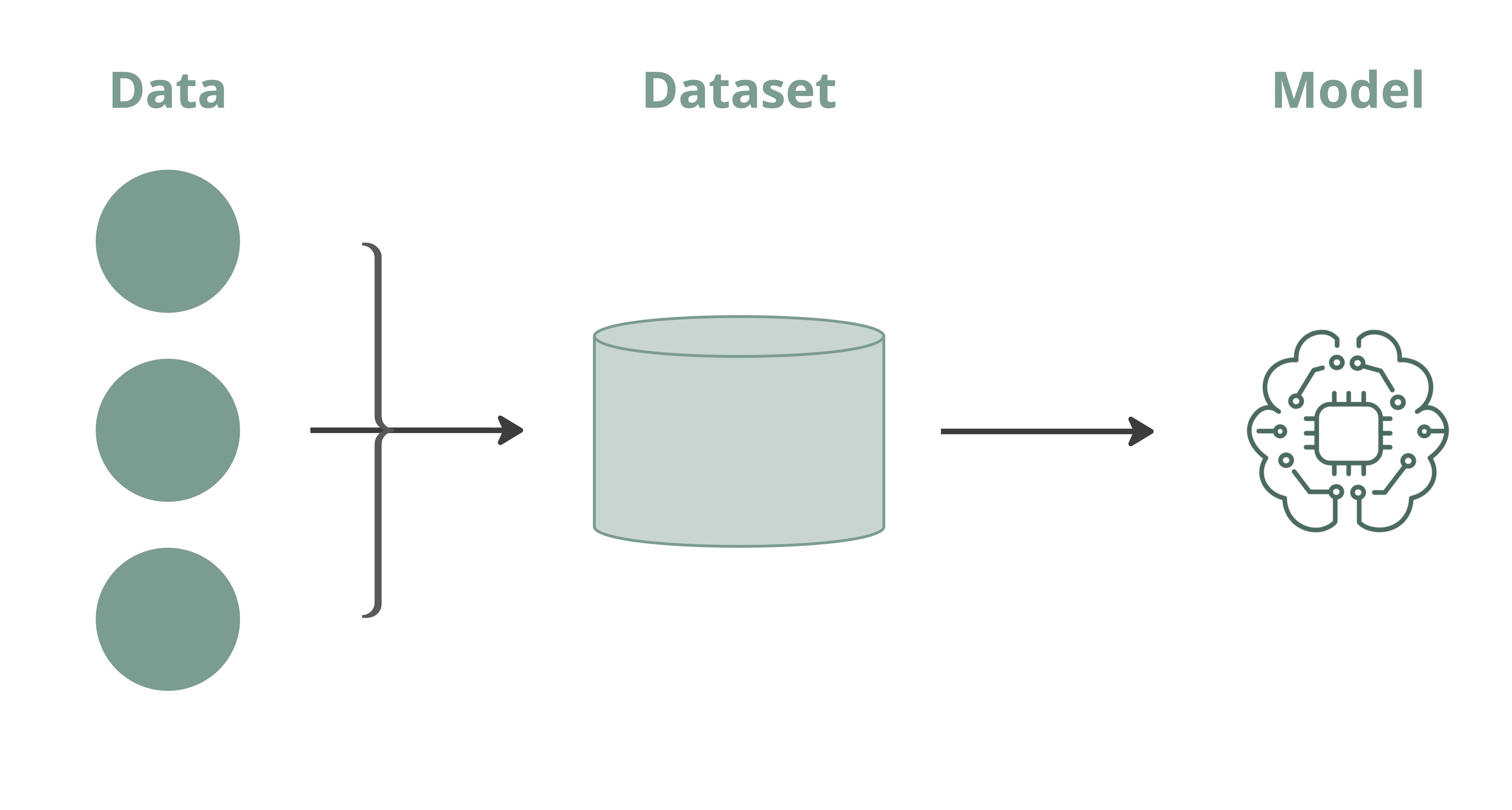
A given model version is always trained on a specific dataset version, which is composed of specific versions of underlying data. Traceability between these elements is crucial to understand changes in model performance. Version control is also important to ensure that frozen models are deployed following regulatory authorisation. Finally, traceability between the version of the model and the dataset should be maintained in cases where rollback may be required.
Data storage controls should also ensure that training and test data is sequestered to prevent data leakage. The goal of model evaluation is to understand performance and generalisability on unseen data. When test and training datasets are not separated, overly optimistic model performance will be estimated that will perform far worse on truly unseen data in clinical practice. Training and test data sequestration can be implemented by:
- Data sequestration strategy early (in the Data Management Plan). For example, the data split ratio before collection, such as 70% training, 15% validation, and 15% test.
- Organizational or structural separation by storing training, validation, and test datasets in separate locations or directories, and by making it technically difficult (or impossible) to accidentally merge them. Technical controls available in tools like MLflow, Azure ML, and SageMaker should be used where possible to enforce sequestration.
- Access and permission restrictions for development team members.
Expert’s Secret #4: Implement robust data versioning and sequestration controls for each AI function to maintain data integrity and ensure robust model performance.
Conclusion
Data management for AI-enabled medical devices is a foundational element of device development that regulators expect to see embedded within quality systems from the outset. The regulatory landscape has shifted dramatically in the last 5 years, and companies that establish robust data management practices today will be well-positioned to create safe and effective devices and demonstrate compliance confidently.
Practical data management strategies in this article will ensure AI-enabled devices are trustworthy and perform as intended throughout the device lifecycle. Companies that treat data management as a strategic priority rather than a compliance checkbox will build and maintain a competitive advantage in an increasingly complex regulated landscape.
About the Expert
Richie Christian is a Senior Medical Device Consultant at wega Informatik where he helps teams secure FDA clearances and build quality systems that work. He has 11+ years’ experience in medical device quality management systems and regulatory affairs and is driven by a simple belief: the MedTech community deserves clear, practical guidance without the fluff.

